① DB에서 인덱스를 사용하는 이유
-
DB에 저장한 데이터는 HDD와 같은 저장매체에 저장되고, 각 데이터는 HDD의 주소와 매핑된다.
- DB에서 어떠한 데이터를 SELECT 하는 경우, DB(HDD)에서 전체 내용을 검색한다(Full Scan).
- 경우에 따라, 데이터 1건을 찾기 위해 HDD 전체 내용을 뒤져야 하는 경우 시간 소모가 많이 발생한다.
- 하지만, 찾고자 하는 데이터와 그 데이터가 저장된 주소값이 매핑 테이블로 관리되고 있다면, 찾고자 하는 데이터의 주소값에 직접 접근할 수 있으므로 Full Scan 보다 시간을 획기적으로 단축시킬 수 있다.
- 이러한 원리로 이용하는 것이 DB index이며, index는 데이터와 그 데이터가 저장된 주소값(row id)으로 관리 된다.
- 인덱스 생성시 원래 테이블에 있던 데이터는 그대로 두고, 다른 메모리 영역(pga라는 sort area, temporary table space)로 데이터를 가져와서, Indexing 정의에 따라 HDD 블록에 기록된다.
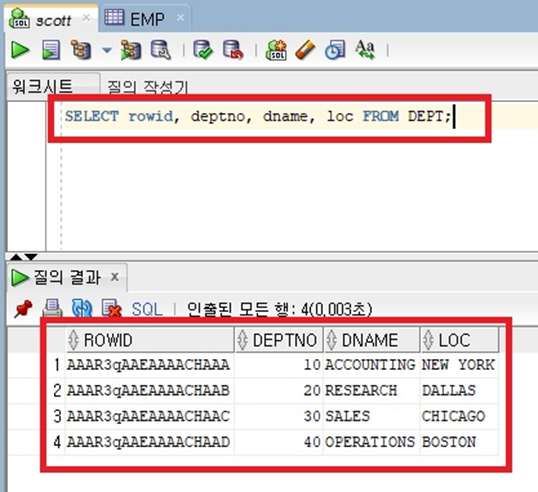
② rowid를 구성하는 18자리 의미
- 6자리 : data object 번호
- 3자리 : 파일 번호
- 6자리 : 파일의 block 번호
- 3자리 : row 번호 (테이블 내에서 몇번째 위치)
③ 인덱스 생성 방법
- Unique Index
- 명령어) create unique index 인덱스명 on 테이블명(컬럼명);


- Non-Unique Index
- 명령어) create index 인덱스명 on 테이블명(컬럼명);


④ 인덱스 확인 및 삭제
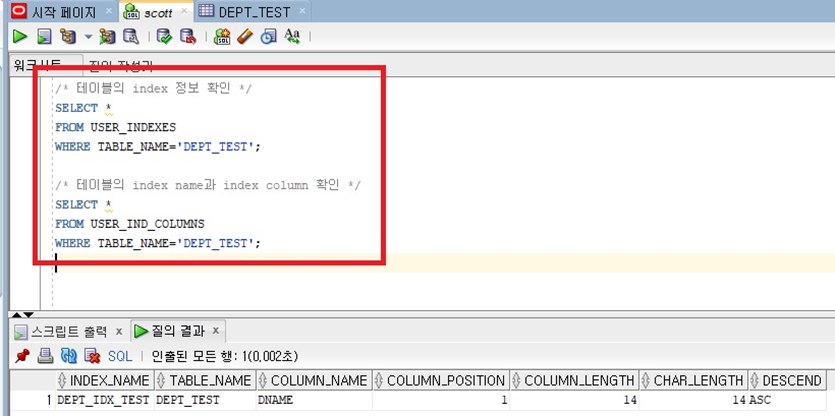
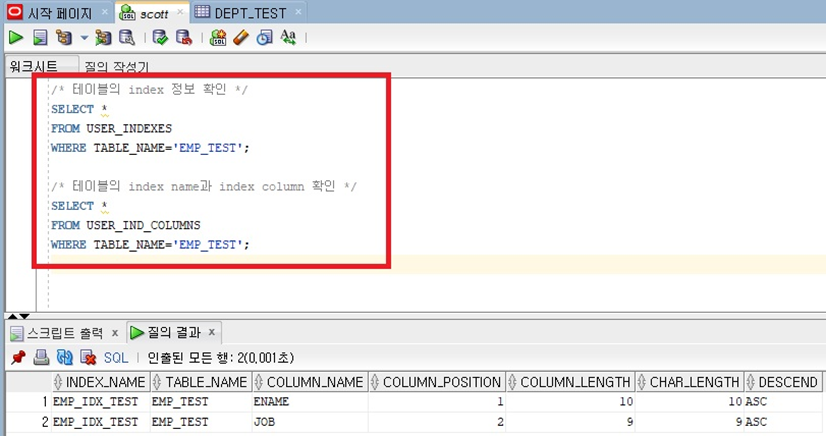
- 테이블에 설정된 Index 정보 확인
- 명령어) SELECT * FROM USER_INDEXES WHERE TABLE_NAME='[테이블명]';
- 명령어) SELECT * FROM USER_IND_COLUMNS WHERE TABLE_NAME='[테이블명]';
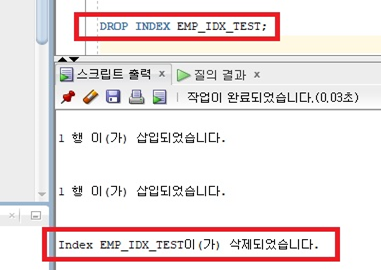
- 인덱스 삭제 명령어) DROP INDEX [인덱스명];
⑤ 인덱스 종류
- B-Tree 인덱스 : 데이터 종류(colum 수)가 많으면서, 데이터(row 수)가 적은 경우 사용.
- FBI(Function Based Index, 함수 기반 인덱스) : WHERE절에서 index로 설정한 컬럼이 함수와 엮이게 되면, index 효과가 나타나지 않음.
- Decending Index (내림차순 인덱스) : 설정한 컬럼을 기준으로 내림차순 정렬
- Composit Index (결합 인덱스) : 두개 이상의 컬럼들을 합쳐서 하나의 index로 생성
- Bitmap 인덱스 : 데이터가 있는 자리만 1로 표시하고, 그렇지 않은 행은 0으로 표시해서 map을 구성해서 관리하는 방식으로 새로운 데이터가 추가되거나 수정되면 bitmap을 다시 생성해야 하는 단점이 있지만 성능은 좋다.
⑥ Index와 성능의 관계
- 인덱스를 생성하면 성능이 좋아진다? 경우에 따라서 full-scan보다 늦어질 수 있다.
- INSERT 경우,
인덱스가 없는 테이블) 그냥 넣으면 된다.
인덱스가 있는 테이블) 정렬순서대로 insert해야 하므로 테이블이 갈라지면서 여러번에 걸쳐 작업해야 한다.
(index split 현상)
- DELETE 경우,
인덱스가 없는 테이블) 그냥 지워진다.
인덱스가 있는 테이블) 테이블에서는 데이터가 지워졌지만, 인덱스에서는 지워지지 않고 사용하지 않는 표시.
이러한 경우가 누적되면 쿼리 속도가 늦어질 수 있다.
- UPDATE 경우,
인덱스가 있는 테이블) DELETE 후 INSERT 작업을 하므로 부하가 발생한다.
⑦ Index Rebuild
- index 작업 후 취약점 또는 개선사항 발견 후, index를 새롭게 구성하는 것.
- index를 한번 생성해 놓았다고해서 영구적으로 좋은 성능을 유지할 수 없기 때문에 꾸준한 관리가 필요.
- 명령어) analyze index [ 테이블명] validate structure;
- 명령어) alter index [테이블명] rebuild;
⑧ Invisible Index
- index 삭제 전 사용안함 상태로 만들어 테스트할 수 있는 기능.
- 명령어) alter index [인덱스명] invisible;
- 관련 명령어) alter index [인덱스명] visible;
'설정' 카테고리의 다른 글
| 네트워크 관련 리눅스 CLI 명령어 (man, lsof, nslookup, telnet, netstat) (0) | 2024.06.02 |
|---|---|
| SCP(Secure CoPy) 명령어 (1) | 2024.06.02 |
| MariaDB conf.d 및 initdb.d 초기화 설정 (docker, docker-compose) (1) | 2024.01.14 |
| 가비아에서 구매한 도메인을 AWS EC2에 직접 연결 (안됨) (0) | 2023.11.03 |
| docker-compose 주요 명령어 (0) | 2023.08.19 |