
1. numpy 자료형
① 종류
- i : integer
- u : unsigned integer
- f : single precision float
- d : double precision float
- b : bool
- D : complex
- S : string
- U : Unicode
② 정수형 (int : integer)
- 부호 있는 정수형 : int8, int16, int32, int 64
- 부호 없는 정수형 : uint8, uint16, uint32, uint64
③ 복소수 (complex)
- complex64 : 두 개의 32bit float형으로 실수와 허수부 구성
- complex128 : 두 개의 64bit float형으로 실수와 허수부 구성
④ 특징
- numpy 배열의 모든 요소는 동일한 자료형으로 구성된다.
- 각각의 자료형은 다른 자료형으로 변환할 수 있는 함수를 제공한다.
- 복소수를 정수 또는 실수형으로 변환할 수 없다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# .int_()
>>> a = np.int_( [1, 2, 3, 4, 5] )
>>> a
array([1, 2, 3, 4, 5])
>>> type(a)
<class 'numpy.ndarray'>
>>> a.dtype
dtype('int32')
# _를 하지않고 하면
>>> b = np.int( [1, 2, 3, 4, 5] )
Traceback (most recent call last):
File "<pyshell#21>", line 1, in <module>
b = np.int( [1, 2, 3, 4, 5] )
TypeError: int() argument must be a string, a bytes-like object or a number, not 'list'
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
# .int()
# int 사용이 안되는건 아님.
>>> b = np.int(190)
>>> b
190
>>> type(b)
<class'int'>
>>> b.dtype
Traceback (most recent call last):
File "<pyshell#32>", line 1, in <module>
b.dtype
AttributeError: 'int' object has no attribute 'dtype'
>>> c = int(111)
>>> c
111
>>> type(c)
<class 'int'>
>>> c.dtype
Traceback (most recent call last):
File "<pyshell#39>", line 1, in <module>
c.dtype
AttributeError: 'int' object has no attribute 'dtype'
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
# .float_()
# float_로 실수 지정
>>> x = np.float_(4)
>>> x
4.0
>>> x.dtype
dtype('float64')
# float32로 지정
>>> x = np.float32(99)
>>> x
99.0
>>> x.dtype
dtype('float32')
>>> type(x)
<class 'numpy.float32'>
# float_ 배열 생성
>>> ar = np.float_( [1, 2, 3, 4, 5] )
>>> ar
array([1., 2., 3., 4., 5.])
>>> ar.dtype
dtype('float64')
>>> ar = np.float( [1, 2, 3, 4, 5] )
Traceback (most recent call last):
File "<pyshell#39>", line 1, in <module>
ar = np.float( [1, 2, 3, 4, 5] )
TypeError: float() argument must be a string or a number, not 'list'
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
# dtype=np.데이터타입
# 타입 지정1
>>> ar1 = np.arange( 10, dtype=np.uint8 )
>>> ar1
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8)
>>> ar1.dtype
dtype('uint8')
# 타입 지정2
>>> ar2 = np.arange( 10, dtype="uint8" )
>>> ar2
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8)
>>> ar2.dtype
dtype('uint8')
# 타입 지정3
>>> ar3 = np.arange( 10, dtype='u' )
Traceback (most recent call last):
TypeError: data type "u" not understood
>>> ar3 = np.arange( 10, dtype='u8' )
>>> ar3
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint64)
>>> ar3.dtype
dtype('uint64')
>>> ar3 = np.arange( 10, dtype='u4' )
>>> ar3
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint32)
>>> ar3 = np.arange( 10, dtype='u2' )
>>> ar3
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint16)
>>> ar3 = np.arange( 10, dtype='u1' )
>>> ar3
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8)
>>> ar3 = np.arange( 10, dtype='<u1' )
>>> ar3
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8)
>>> ar3 = np.arange( 10, dtype='>u1' )
>>> ar3
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8)
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
# 자료형 확인 - np.issubdtype
>>> ar = np.arange( 10, dtype=np.uint32 )
>>> ar
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint32)
>>> ar1 = ar.astype( np.float64 )
>>> ar1
array([0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])
>>> ar1.dtype
dtype('float64')
>>> ar
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint32)
>>> ar1
array([0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])
>>> np.issubdtype( ar.dtype, np.integer )
True
>>> np.issubdtype( ar.dtype, np.float )
Warning (from warnings module):
File "<pyshell#260>", line 1
In future, it will be treated as `np.float64 == np.dtype(float).type`.
False
>>> np.issubdtype( ar.dtype, np.floating )
False
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# int, float, str 자료형 변환
>>> ar = np.arange( 10, dtype=np.uint8 )
>>> ar
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8)
>>> ar.dtype
dtype('uint8')
>>> ar1 = ar.astype( int )
>>> ar1
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> ar1.dtype
dtype('int32')
>>> ar2 = ar.astype( float )
>>> ar2
array([0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])
>>> ar2.dtype
dtype('float64')
|
cs |
2. 인덱싱: 배열 요소 참조
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# 기본 인덱싱
>>> ar = np.arange(10)
>>> ar
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>>
>>> ar[ 4 : 7 ]
array([4, 5, 6])
# 범위를 지정한 요소들의 값을 한번에 변경.
>>> ar[ 4:7 ] = 0
>>> ar
array([0, 1, 2, 3, 0, 0, 0, 7, 8, 9])
# [ : ]
>>> ar[ : ]
array([0, 1, 2, 3, 0, 0, 0, 7, 8, 9])
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
# 2차원 배열 부터는 조금 헤갈림.
# 1차원 배열과는 달리 , 좌우로 행, 열로 분리.
>>> arar = np.array( [[1, 2, 3], [4, 5, 6], [7, 8, 9]] )
>>> arar
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
>>> ar25size = np.arange(1, 26).reshape(5, 5)
>>> ar25size
array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]])
# 3행(인덱스)만 출력하는 방법
>>> ar25size[ 3, : ]
array([16, 17, 18, 19, 20])
>>> print( ar25size[ 3, : ] )
[16 17 18 19 20]
>>> ar25size[ 3, ]
array([16, 17, 18, 19, 20])
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
# 24를 출력하시오?
# 13을 출력하시오?
>>> ar25size
array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]])
>>> ar25size[ 4, 3 ]
24
>>> ar25size[ 2, 2 ]
13
# 17, 18, 19를 출력하시오?
# 22, 23을 출력하시오?
>>> ar25size
array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]])
>>> ar25size[ 3, 1:4 ]
array([17, 18, 19])
>>> ar25size[ 4, 1:3 ]
array([22, 23])
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
# 2행만 출력하시오? 11 12 13 14 15
>>> ar25size
array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]])
>>> ar25size[ 2 : 3 ]
array([[11, 12, 13, 14, 15]])
# 2, 3행 두행을 출력하시오?
>>> ar25size[ 2 : 4 ]
array([[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20]])
# 2, 3, 4행을 출력하시오?
>>> ar25size[ 2 : 5 ]
array([[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]])
>>> ar25size[ 2 : ] #이것도 위와 동일!
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
# 4행만 출력하시오? (다양한 방법으로 출력)
>>> ar25size
array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]])
>>> ar25size[ 4 ]
array([21, 22, 23, 24, 25])
>>> ar25size[ 4, : ]
array([21, 22, 23, 24, 25])
>>> ar25size[ 4, ]
array([21, 22, 23, 24, 25])
>>> ar25size[ -1 ]
array([21, 22, 23, 24, 25])
>>> ar25size[ -1, : ]
array([21, 22, 23, 24, 25])
>>> ar25size[ -1, ]
array([21, 22, 23, 24, 25])
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# 역인덱스
>>> ar25size
array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]])
>>> ar25size[ -1 ]
array([21, 22, 23, 24, 25])
>>> ar25size[ -2 ]
array([16, 17, 18, 19, 20])
>>> ar25size[ -3 ]
array([11, 12, 13, 14, 15])
>>> ar25size[ -4 ]
array([ 6, 7, 8, 9, 10])
>>> ar25size[ -5 ]
array([1, 2, 3, 4, 5])
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# 열(Column) 기준으로 인덱싱
# 각 행의 2열 값만 출력하시오?
# 3, 8, 13, 18, 23
>>> ar25size
array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]])
>>> ar25size[ : , 2 ]
array([ 3, 8, 13, 18, 23])
>>> ar25size[ , 2 ]
SyntaxError: invalid syntax
# 각 행의 4열 값만 출력하시오?
>>> ar25size[ : , 4 ]
array([ 5, 10, 15, 20, 25])
>>> ar25size[ : , -1 ]
array([ 5, 10, 15, 20, 25])
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# 열(Column) 기준 역인덱싱
>>> ar25size
array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]])
>>> ar25size[ : , -1 ]
array([ 5, 10, 15, 20, 25])
>>> ar25size[ : , -2 ]
array([ 4, 9, 14, 19, 24])
>>> ar25size[ : , -3 ]
array([ 3, 8, 13, 18, 23])
>>> ar25size[ : , -4 ]
array([ 2, 7, 12, 17, 22])
>>> ar25size[ : , -5 ]
array([ 1, 6, 11, 16, 21])
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# 3미만인 열(인덱스)의 값을 출력?
# 먼저 배열에서 어떤 부분을 출력하는지 파악!
>>> ar25size
array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]])
>>> ar25size[ : , :3 ] #미만은 3이 포함 안됨.
array([[ 1, 2, 3],
[ 6, 7, 8],
[11, 12, 13],
[16, 17, 18],
[21, 22, 23]])
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# 3미만인 열(인덱스)의 값을 출력?
# 먼저 배열에서 어떤 부분을 출력하는지 파악!
>>> ar25size
array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]])
>>> ar25size[ : , :3 ] #미만은 3이 포함 안됨.
array([[ 1, 2, 3],
[ 6, 7, 8],
[11, 12, 13],
[16, 17, 18],
[21, 22, 23]])
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
# 2, 3, 4, 7, 8, 9 값을 0으로 채우시오?
>>> ar25size
array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]])
# 먼저 해당 부분만 출력.
>>> ar25size[ :2 , 1:4 ]
array([[2, 3, 4],
[7, 8, 9]])
# 그리고 0으로 입력.
>>> ar25size[ :2 , 1:-1 ] = 0
>>> ar25size
array([[ 1, 0, 0, 0, 5],
[ 6, 0, 0, 0, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]])
|
cs |
3. View
① 개요
- 기본적인 인덱싱으로 넘파이 배열에 대한 뷰(View)를 만들 수 있다.
- ‘뷰’란 원본 배열의 일부분에 접근하기 위해서 만든 하나의 작은 배열 개념으로 보면 된다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# [][] 방법으로 색인
>>> ar30size
array([[ 1, 2, 3, 4, 5, 6],
[ 7, 8, 9, 10, 11, 12],
[13, 14, 15, 16, 17, 18],
[19, 20, 21, 22, 23, 24],
[25, 26, 27, 28, 29, 30]])
>>> ar30size[0]
array([1, 2, 3, 4, 5, 6])
>>> ar30size[2]
array([13, 14, 15, 16, 17, 18])
>>> ar30size[4]
array([25, 26, 27, 28, 29, 30])
>>> ar30size[-1]
array([25, 26, 27, 28, 29, 30])
>>> ar30size[4][4]
29
|
cs |
- 메모리상에 ‘뷰’를 위한 원본 배열의 사본을 만들지 않기 때문에 ‘뷰’ 자체는 아무리 많이 만들어도 괜찮다.
- ‘뷰’ 자체를 만든 정도의 메모리 사용량만 늘어날 뿐이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# # [][] 방법으로 8~12 요소들만 출력하시오?
>>> ar25size
array([[ 1, 2, 3, 4, 5, 6],
[ 7, 8, 9, 10, 11, 12],
[13, 14, 15, 16, 17, 18],
[19, 20, 21, 22, 23, 24],
[25, 26, 27, 28, 29, 30]])
>>> ar25size[ 1 ][ 1: ]
array([ 8, 9, 10, 11, 12])
>>> ar25size[ -1 ][ 2:5 ] #27 28 29
array([27, 28, 29])
|
cs |
- ‘뷰’를 통해서 원본 배열의 일부분을 수정하게 되면 원본에도 영향을 끼치기 때문에 원본의 요소도 변경된다는 것을 주의하자!
- 따라서 ‘뷰’는 단순히 어떤 원본 배열의 일부분을 보기(=접근하기, 참조하기)위한 ‘뷰’일 뿐이다. 라는 생각을 잊지말자!
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# a 변수에 담아서 값을 변경해보시오?
>>> ar30size
array([[ 1, 2, 3, 4, 5, 6],
[ 7, 8, 9, 10, 11, 12],
[13, 14, 15, 16, 17, 18],
[19, 20, 21, 22, 23, 24],
[25, 26, 27, 28, 29, 30]])
>>> a = ar25size[-1][ 2:5 ]
>>> a
array([27, 28, 29])
>>> a[-1] = 0
>>> a
array([27, 28, 0])
>>> ar30size
array([[ 1, 2, 3, 4, 5, 6],
[ 7, 8, 9, 10, 11, 12],
[13, 14, 15, 16, 17, 18],
[19, 20, 21, 22, 23, 24],
[25, 26, 27, 28, 0, 30]])
|
cs |
4. numpy 고유 인덱싱 방법
① 개념
- 예를 들어, [ 1, 1: ]와 같이 배열 요소에 접근하는 방식이 넘파이 고유 인덱싱 방식이다.
- 파이썬 중첩 리스트에서는 이와 같은 방식으로 요소에 접근하면 에러가 발생한다.
|
1
2
3
4
5
6
7
8
9
|
>>> ar30size
array([[ 1, 2, 3, 4, 5, 6],
[ 7, 8, 9, 10, 11, 12],
[13, 14, 15, 16, 17, 18],
[19, 20, 21, 22, 23, 24],
[25, 26, 27, 28, 0, 30]])
>>> ar30size[ 1, 1: ]
array([ 8, 9, 10, 11, 12])
|
cs |
- 파이썬 배열 접근과 넘파이가 지정된 요소에 접근하는 방식을 구별하여 사용한다.
- 넘파이 고유 인덱싱 방식이 더 빠르기 때문에 가능한 넘파이 고유 방식을 사용한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
>>> ar2d_np = np.array( [[1, 2, 3, 4, 5], [6, 7, 8, 9, 10]] )
>>> ar2d_np
array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10]])
>>> ar2d_np = np.array( [[1, 2, 3, 4, 5], [6, 7, 8, 9, 10]] )
>>> ar2d_np
array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10]])
|
cs |
② 짝수 또는 홀수 행렬 출력
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# for문을 이용하여 홀수행만 출력
>>> ar30size = np.arange(1, 31).reshape(5, 6)
>>> ar30size
array([[ 1, 2, 3, 4, 5, 6],
[ 7, 8, 9, 10, 11, 12],
[13, 14, 15, 16, 17, 18],
[19, 20, 21, 22, 23, 24],
[25, 26, 27, 28, 29, 30]])
>>> for i in range(5): # 5 대신 ar30size[ ar30size.shape[0] ]
if i % 2 == 0:
print( ar30size[i] )
[1 2 3 4 5 6]
[13 14 15 16 17 18]
[25 26 27 28 29 30]
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# for문을 이용하여 홀수열만 출력
>>> ar30size = np.arange(1, 31).reshape(5, 6)
>>> ar30size
array([[ 1, 2, 3, 4, 5, 6],
[ 7, 8, 9, 10, 11, 12],
[13, 14, 15, 16, 17, 18],
[19, 20, 21, 22, 23, 24],
[25, 26, 27, 28, 29, 30]])
>>> for i in range(5): # 5 대신 ar30size[ ar30size.shape[0] ]
for j in range(6): # 6 대신 ar30size[ ar30size.shape[1] ]
if j % 2 == 0:
print( ar30size[i][j], end=‘ ‘ )
print()
1 3 5
7 9 11
13 15 17
19 21 23
25 27 29
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
# for문 대신 numpy 방식으로 출력
>>> ar30size
array([[ 1, 2, 3, 4, 5, 6],
[ 7, 8, 9, 10, 11, 12],
[13, 14, 15, 16, 17, 18],
[19, 20, 21, 22, 23, 24],
[25, 26, 27, 28, 29, 30]])
# 홀수 행만 출력
>>> ar30size[ : : 2 ]
array([[ 1, 2, 3, 4, 5, 6],
[13, 14, 15, 16, 17, 18],
[25, 26, 27, 28, 29, 30]])
# 짝수 행만 출력
>>> ar30size[ 1 : : 2 ]
array([[ 7, 8, 9, 10, 11, 12],
[19, 20, 21, 22, 23, 24]])
>>> ar30size[ : : 3 ]
array([[ 1, 2, 3, 4, 5, 6],
[19, 20, 21, 22, 23, 24]])
|
cs |
5. Broadcasting
① 개요
- umpy에서는 형상(모양)이 다른 배열간의 연산을 효율적으로 그리고 빠르게 처리하기 위해서 형상(모양)을 맞춰서 연산시키려 한다.
- 이러한 것을 배열 연산을 위한 ‘확장’이라고 표현하며 브로드캐스팅 처리라고 한다.
- 즉, 넘파이 내부에서 형상(모양)이 다른 배열간의 효율적인 연산을 처리하기 위해서 배열의 형상(모양)을 확장시키는 것이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# ndarray에 스칼라(상수) 3 값 더하기
>>> a = np.array( [1, 2, 3, 4, 5] )
>>> a
array([1, 2, 3, 4, 5])
>>> a.ndim
1
>>> a.shape
(5,)
>>> a.size
5
# a 배열에 스칼라 3을 더하면?
>>> a + 3
array([4, 5, 6, 7, 8])
# 이런 연산이 가능한 이유는
# 넘파이에서 '브로드캐스팅' 처리하여 이러한 계산을 가능하도록 해주기 때문이다.
# '브로드캐스팅'은 넘파이 모듈 내부에서 자동으로 수행되어,
# 스칼라 3은 넘파이 내부에서 np.array([3, 3, 3, 3, 3])로 확장되어 계산된다.
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# 넘파이는 형상이 다르면 연산이 오류가 발생한다.
>>> a = np.array( [1, 2, 3, 4, 5] )
>>> b = np.array( [1, 2, 3] )
>>> a
array([1, 2, 3, 4, 5])
>>> b
array([1, 2, 3])
>>> a + b
Traceback (most recent call last):
File "<pyshell#116>", line 1, in <module>
a + b
ValueError: operands could not be broadcast together with shapes (5,) (3,)
# 앞서의 스칼라 연산하고는 다르게 오류가 발생했다.
# 그럼 스칼라 연산을 다시 해보자.
>>> a + 1
array([2, 3, 4, 5, 6])
>>> b + 2
array([3, 4, 5])
|
cs |
② 규칙
- 스칼라 값과의 연산은 브로드캐스팅이 가능하다.
- 차원이 같거나 어느 한쪽의 배열 크기가 1인 경우(행이든 열이든) 브로드캐스팅이 가능하다.
- 차원에 대해 축(Axis)의 길이가 동일하다면 브로드캐스팅이 가능하다.
|
1
2
3
4
5
6
7
8
9
10
|
>>> a = np.ones( (4, 4) )
>>> b = np.arange(4)
>>> # a + b 연산 결과는?
>>> a + b
array([[1., 2., 3., 4.],
[1., 2., 3., 4.],
[1., 2., 3., 4.],
[1., 2., 3., 4.]])
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
# 브로드캐스팅 기본개념 이해2
>>> a = np.arange(5).reshape(5, 1)
>>> b = np.arange(5)
>>> a
array([[0],
[1],
[2],
[3],
[4]])
>>> b
array([0, 1, 2, 3, 4])
>>> a + b
array([[0, 1, 2, 3, 4],
[1, 2, 3, 4, 5],
[2, 3, 4, 5, 6],
[3, 4, 5, 6, 7],
[4, 5, 6, 7, 8]])
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
# 브로드캐스팅 기본개념 이해3
>>> a = np.arange(5).reshape(5, 1)
>>> b = np.arange(3)
>>> a
array([[0],
[1],
[2],
[3],
[4]])
>>> b
array([0, 1, 2, 3, 4])
>>>
>>> a + b
|
cs |
6. indexing, slicing
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
>>> a = np.array( [1, 2, 3, 4, 5, 6, 7, 8, 9] )
>>> a
array([1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> a[ 4 : 8 ]
array([5, 6, 7, 8])
>>> a[ 5 : -1 ]
array([6, 7, 8])
>>> a[ 1 : 4 : 2 ]
array([2, 4])
>>> a[ 3 : 8 : 2 ]
array([4, 6, 8])
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
>>> a = np.arange(1, 10).reshape(3, 3)
>>> a
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
>>> a[0]
array([1, 2, 3])
>>> a[1]
array([4, 5, 6])
>>> a[2]
array([7, 8, 9])
>>> a[0][1]
2
>>> a[2][2]
9
|
cs |
7. 3차원 배열
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# 3차원 배열 생성
>>> a = np.array([[[1, 2, 3, 4],[1, 2, 3, 4],[1, 2, 3, 4]],[[1, 2, 3, 4],[1, 2, 3, 4],[1, 2, 3, 4]]])
>>> a
array([[[1, 2, 3, 4],
[1, 2, 3, 4],
[1, 2, 3, 4]],
[[1, 2, 3, 4],
[1, 2, 3, 4],
[1, 2, 3, 4]]])
>>> a.shape
(2, 3, 4)
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
# 3차원 배열 인덱싱
>>> a = np.arange(27).reshape(3, 3, 3)
>>> a
array([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8]],
[[ 9, 10, 11],
[12, 13, 14],
[15, 16, 17]],
[[18, 19, 20],
[21, 22, 23],
[24, 25, 26]]])
>>> a[0]
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
>>> a[0, 2]
array([6, 7, 8])
>>> a[0, 2, -1]
8
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# 3차원 배열 슬라이싱
>>> a
array([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8]],
[[ 9, 10, 11],
[12, 13, 14],
[15, 16, 17]],
[[18, 19, 20],
[21, 22, 23],
[24, 25, 26]]])
>>> a[ -1, -1, :2 ]
array([24, 25])
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# 3차원 배열 슬라이싱
>>> a = np.arange(1, 51).reshape( _______________ )
>>> a
array([[[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]],
[[26, 27, 28, 29, 30],
[31, 32, 33, 34, 35],
[36, 37, 38, 39, 40],
[41, 42, 43, 44, 45],
[46, 47, 48, 49, 50]]])
>>>_________________________________________
array([[37, 38, 39],
[42, 43, 44],
[47, 48, 49]])
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
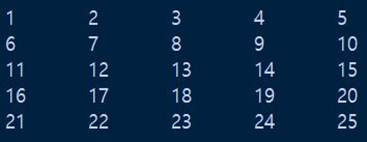
# (문제) 2차원 배열과 3차원 배열을 각각 arange()로 생성한 후 각 요소들의 값을 for문으로 출력하시오? 이때, 2차원 배열의 요소 수는 25개로 하고 3차원 배열의 요소 수는 60개로 한다.
>>> ar2d = np.arange( 1, 26 ).reshape( 5, 5 )
>>> ar2d
array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]])
>>> for x_ in range(0, 5):
for y_ in range(0, 5):
ar2d[x_][y_] = a[x_][y_]
print( ar2d[x_][y_], end='\t' )
print()
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
>>> ar3d = np.arange( 1 , 61 ).reshape( 3, 4, 5 )
>>> ar3d
array([[[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20]],
[[21, 22, 23, 24, 25],
[26, 27, 28, 29, 30],
[31, 32, 33, 34, 35],
[36, 37, 38, 39, 40]],
[[41, 42, 43, 44, 45],
[46, 47, 48, 49, 50],
[51, 52, 53, 54, 55],
[56, 57, 58, 59, 60]]])
for x_ in range(0, 3):
for y_ in range(0, 4):
for z_ in range(0, 5):
ar3d[x_][y_][z_] = ar3d[x_][y_][z_]
print( ar3d[x_][y_][z_], end='\t' )
print()
print()
|
cs |

'파이썬' 카테고리의 다른 글
| 유튜브 자막추출 파이썬 코드 (feat. yotube_transcript_api 라이브러리) (5) | 2024.09.07 |
|---|---|
| 텍스트 음성변환(SST; SpeechToText) 파이썬 코드 (1) | 2024.09.07 |
| numpy 사용법 기초 (1/2) (3) | 2024.09.07 |
| wxPython 라이브러리 설치 및 기본 사용법 (1) | 2024.09.07 |
| 우분투(Ubuntu) 환경에서 파이썬 설치 매뉴얼 문서(word) (0) | 2024.06.12 |